

Your CRM Doesn't Learn. Here's What a System That Does Looks Like Under the Bonnet.
8 learning systems. 6 feedback loops. Zero prompts manually edited. A look underneath the dashboard everyone wants to show you.

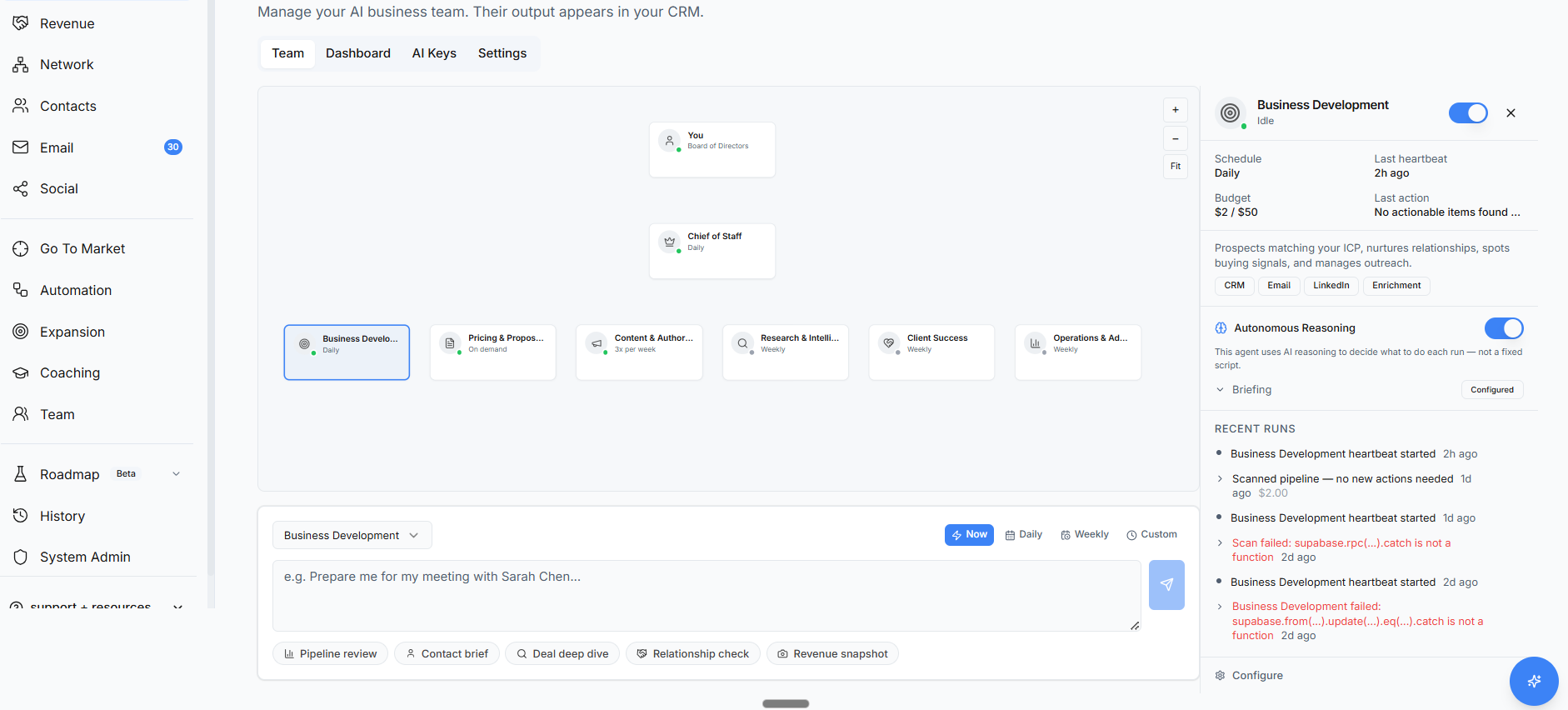
This is the bit that’s easy to show.
A clean dashboard. Agent cards with names like “Chief of Staff” and “Business Development.” Status badges. Budget meters. A toggle switch you can flip on. Every emerging market leader AI product has a version of this screen. It’s the moment in the demo where someone says “and here’s your AI team” and waits for you to be impressed.
I’ve sat through dozens of these demos. And every time, the same question nags at me. What actually happens when someone flips that toggle?
Because here’s what usually happens behind the scenes. Your data gets sent to a language model. A response comes back. Done. The model doesn’t remember your last conversation. It doesn’t know your client Sarah always raises procurement concerns in the third meeting. It doesn’t know that your deals stall 40% longer than your team’s average.
It starts from zero every single time.
That’s not intelligence. That’s autocomplete with a billing page.
I spent the past year building something different.
Not because I set out to build an AI company. I kept hitting the same wall: the AI features in every tool I tried were disposable. Impressive for ten minutes. Useless by Friday. I’d configure something, feel that little buzz of possibility, and then watch it give me the exact same generic output a week later. Nothing had changed. Nothing had learned.
So I started asking a different question.
Not “how do I add AI to a business tool?” but “what would it take to build AI that actually gets smarter the longer you use it?”
What follows is what I learned. Some of this is specific to what we built at Nynch. Most of it applies to anyone thinking seriously about AI in their business.
What “Learning” Actually Means
The word “learning” gets thrown around loosely in AI marketing. Every product claims it. Almost none of them deliver it. So let me be specific about what I mean, because this distinction changed everything about how I approached the problem.
Most software tracks what you did. You sent an email. You had a meeting. You moved a deal forward. That’s recording actions. Useful, but it’s just a fancy logbook.
A learning system goes further. It tracks what happened because of what you did. Did that email get a reply?
Did that meeting result in a second one?
Did the deal actually land?
Recording outcomes, not just actions. That’s the first requirement.
The second is connecting outcomes back to inputs. Not just “this email got a reply” but “this email got a reply because it was under 150 words and led with a specific question, sent to a finance director on a Tuesday morning.” The system traces the thread between what you did and what happened next. Then it adjusts future behaviour based on that connection.
The third is compounding across time and across domains. This is the one most people miss. A learning in one part of the system should improve behaviour in another part. If your deal analysis discovers that a certain type of client always raises pricing concerns in Q4, that insight should automatically appear in your meeting prep, your email drafts, and your proposal templates. Without anyone copying it from one place to another. Without anyone even knowing the insight exists until it surfaces exactly when it’s needed.
Think of the difference between a notebook and a brilliant colleague. A notebook stores what you write in it. Everything stays exactly where you left it. If you wrote something important on page 14 in January, it’s still sitting there in January. It won’t tap you on the shoulder in March when that information suddenly becomes relevant again.
A brilliant colleague is different. They remember everything. They notice patterns across conversations. They connect a comment you made in January to an observation from last week. They get better at anticipating what you need. Not because they have a better brain. Because they never stop paying attention.
That’s what I set out to build. Here’s what it actually took.
The Architecture Nobody Shows You
Behind every AI dashboard, there’s architecture. And the difference between AI that impresses in a demo and AI that compounds over months comes down to three things: how agents think, how the system remembers, and how it finds what it knows.
How Agents Think
Most products that advertise “AI agents” are running prompt chains. Your data goes in. A pre-written instruction tells the language model what to do. A response comes back. If the response isn’t good enough, there’s no mechanism to try again or think harder. It’s one shot. Take it or leave it.
Let me give you a practical example of why that’s a problem.
Say you ask an AI agent to prepare a briefing for your meeting with a new contact tomorrow. A prompt chain grabs the contact’s name, searches for their company, and returns a paragraph of generic background. Done. One shot.
A real agent thinks differently. On its first pass, it pulls the contact’s details and company background.
Then it pauses and asks itself: what else do I know that’s relevant here?
Second pass. It finds that you’ve had two previous conversations with someone else at that company. One of those conversations mentioned a budget review happening in Q1. Third pass. It checks your deal history and finds that companies in this sector typically take 60% longer to make decisions than your average. Each pass informs the next.
The difference between the two outputs is the difference between a Wikipedia summary and genuine preparation.

We built our agent brain as a loop that runs up to five iterations per task. On each pass, the agent loads only the context relevant to the current step. Not everything it has access to.
Just what matters right now. It outputs its reasoning before taking any action, so there’s always a clear record of why it did something. Then it acts, observes the result, and decides whether another pass would improve the output.
The five-iteration cap matters.
Without it, agents can get stuck in circular reasoning. They ask themselves the same question, get the same answer, and try again indefinitely. Putting a hard ceiling on iterations forces the system to either produce a result or admit it doesn’t have enough information. Both outcomes are better than an infinite loop burning money.
We adapted the core reasoning patterns from an open-source project called OpenClaw. Their work on selective context injection (giving the agent only what it needs, not everything) and planning-before-action (requiring the agent to state its reasoning before doing anything) cut our prompt sizes by 30 to 60 percent and eliminated the circular reasoning problem entirely.
The critical design choice, and this applies to any AI system: agents don’t see everything. A Chief of Staff agent preparing your morning briefing doesn’t need to read every email you’ve ever received. It needs today’s calendar, your active deals, and any overnight signals. Smaller context produces better output and lower cost. Every time.
How AI Remembers
Language models have no memory. Every conversation starts from zero. This is the single biggest gap between what people expect from AI and what they actually get.
Think about that for a moment. You spent twenty minutes explaining your business to ChatGPT last Tuesday. You described your ideal clients. You outlined your pricing model. You shared the nuances of how your industry works. The conversation was excellent. The output was spot on.
Then you came back on Wednesday. And it had no idea any of that happened.
For AI to build up knowledge over time, you need three things working together:
a way to store observations,
a way to retrieve the right ones at the right moment,
and a way to let old observations fade so they don’t clutter the system with outdated noise.
We store five types of memories.
Observations (”Sarah mentioned budget pressure in the Q3 review”).
Decisions (”recommended leading with the ROI angle for this account”).
Outcomes (”deal won, 40% faster than average”).
Preferences (”this user always edits email drafts to be shorter”).
Patterns (”clients in financial services raise compliance concerns 3x more often than other sectors”).
Each memory gets an importance score from 0.0 to 1.0.
High-importance memories persist longer. Low-importance ones decay over time and eventually get cleaned up. This mimics how human memory works. You remember the conversation that changed a deal. You forget the routine check-in that went nowhere.
Retrieval happens through vector embeddings. The idea is simpler than the name suggests. Every memory gets converted into a numerical fingerprint that captures its meaning. When the system needs relevant context (”what do I know about this contact’s concerns?”), it compares the meaning of the question against every stored memory and pulls the closest matches.
Here’s the line I keep coming back to when people ask me how this is different from a chatbot.
Its weights don’t change. Its memories do. And memories, unlike weights, come with evidence you can inspect. You can see exactly which observations led to a recommendation. You can trace the reasoning chain. You can override it if the system got something wrong.
That last part matters more than most people realise. Trust in AI doesn’t come from accuracy alone. It comes from transparency.
When the system says “I recommend leading with risk mitigation for this account,” you should be able to ask “why?” and get a real answer. Not “because the model said so.” But “because the last three deals with similar characteristics stalled when the opening focused on growth, and two of them were lost.”
How AI Finds What It Knows
You might have heard the term “RAG” (Retrieval-Augmented Generation). It’s become the standard approach for making AI work with your own data. The basic version is straightforward: take a question, search a database for relevant information, and feed that information to a language model along with the question.
Most products stop there. One search. One set of results. One answer. Move on.
The problem is that one search often isn’t good enough. And the reason comes down to the fact that there are two completely different ways to search text, and they catch different things.
Vector search finds results by meaning. If you ask “what are Sarah’s concerns about pricing?” it will find notes where someone wrote “the budget won’t stretch that far” even though the word “pricing” never appears. It understands the concept behind the words.
Keyword search (called BM25 in the industry) finds results by exact words. If you search for “Sarah”, you want every document that literally contains her name. Vector search might return documents about other people with similar concerns. Keyword search won’t make that mistake.
You need both. And you need them weighted differently depending on the question. Short, specific queries (”Sarah pricing”) need more keyword weight. Longer, conceptual queries (”what should I know before meeting the Acme team?”) need more semantic weight.
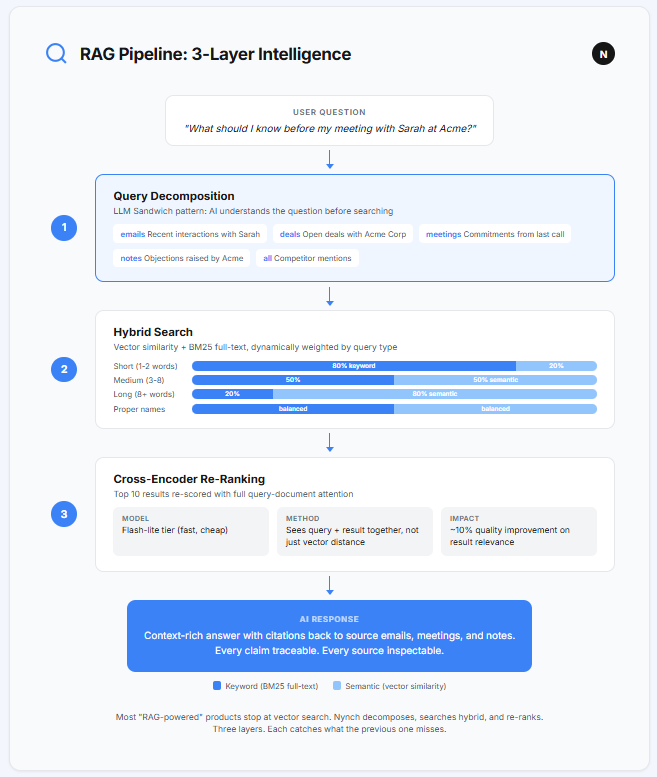
We added a third layer on top. The top 10 results from the combined search get re-scored by a model that sees the full question and each result side by side. This catches relevance signals that the initial search misses. The quality improvement is roughly 10%. Small margin.
But when you’re drafting a proposal from those results, 10% is the difference between a generic document and one that makes the reader think “they really understand our situation.”
Where Real Intelligence Comes From: Feedback Loops
Individual learning systems are useful. An agent that remembers is better than one that doesn’t. A search system that combines meaning and keywords is better than one that uses keywords alone.
But the real shift happens when these systems feed each other.
When a learning in one place automatically improves behaviour somewhere else.
That’s a feedback loop. And it’s where the word “intelligence” starts to actually mean something.
Three loops matter most.
1) Deals teach the system who to target
Here’s what happens in most software when you win a piece of work. A number updates on a dashboard. Someone moves a card to the “Won” column. Maybe there’s a small dopamine hit from seeing the total tick upward. And then everyone moves on to the next thing.
Here’s what happens in a learning system.
The moment a deal is marked as won, the system pulls it apart. It analyses the deal against your Ideal Customer Profile.
What aligned?
What was missing from the profile?
What was different from your assumptions?
It runs that analysis against every other won deal in the system. It looks for patterns you would never spot yourself because you’re too busy delivering the work you just won.
If the system’s confidence in its findings exceeds 70%, it refines your ideal client profile automatically. Below 70%, it queues the findings as suggestions for you to review. You stay in control. But the analysis happens instantly, every time, without being asked.
I watched this play out over three months of testing. The customer profile I typed in on day one looked reasonable. A decade of experience went into it. By month three, the system had quietly rewritten most of it. Not because my instincts were wrong.
Because my instincts were incomplete. That level of specificity was sitting in my data the whole time. I just never had the time or the pattern recognition to extract it.
Losses trigger the same process with different questions. What signals did we miss? What was different about this one? The answers feed back into how the system scores the next opportunity.
After 10 won deals, your customer profile looks nothing like what you originally typed in.
It looks like your actual business. Because it learned from outcomes, not assumptions.
2) Your reactions teach the system what matters to you
This is the loop that changed how I think about AI entirely. And it’s the simplest one to explain.
Every AI-generated notification gets a relevance score from 0.0 to 1.0. Scores above 0.90 interrupt you immediately. Below 0.40, they’re silently dropped. The range between is where the system learns.
Picture your first week. The system doesn’t know you yet. It surfaces everything it thinks might matter. A deal that’s gone quiet. A contact who changed jobs. A birthday. A news article about a company you once emailed. Some of it is gold. Some of it is noise. You know the difference instantly. Thumbs up. Thumbs down. Takes half a second each time.
Now picture week six.
The birthday reminders are gone. You never found them useful, and the system noticed. The deal stall alerts come earlier now, because you responded to every single one. The job change notifications are sharper. They only surface for contacts you’ve actually spoken to in the past 90 days, because the system learned that you ignore the ones about people you barely know.
You never opened a settings page. You never edited a rule. You never wrote a prompt. You never asked for any of this. You just used the system. And the system paid attention.
Behind the scenes, a daily process aggregates all of your feedback by category. Deal stall alerts getting 85% positive feedback? The threshold drops. More of them surface. Contact birthday reminders getting 12% positive? They get filtered out.
The system’s definition of “important” quietly reshapes itself around yours.
This is the loop that makes people say “it feels like it knows me.” It does. Not because someone programmed your preferences into a settings panel. Because you taught it, one thumbs up at a time, without ever realising you were teaching it anything.
3) Patterns propagate across everything
This is the one that surprised me most during development. And it’s the one that makes the whole system more than the sum of its parts.
A finding from deal analysis (”clients who mention competitor X in the first meeting are 2.3 times more likely to request a proof of concept”) doesn’t just stay in deal analysis. It becomes available to meeting prep, email drafting, and proposal generation. Automatically. Without anyone moving it.
Let me show you what that looks like in practice.
You have a meeting tomorrow with Alice. The system prepares your briefing. On the first pass, it pulls Alice’s company details and your last conversation notes. Standard stuff. Any tool could do that.
But then it runs a second pass, informed by what the first pass found. Alice’s company matches three patterns from your lost deals: long procurement cycles, committee decisions, risk-averse culture. Interesting. Third pass. It cross-references this with your relationship data and finds that Alice’s CTO has an engagement score in the top 10% of your entire network.
The output:
“Alice’s company matches 3 of your lost-deal patterns (long procurement cycles, committee decisions, risk-averse culture). But the engagement score with their CTO is in the top 10% of your network. Recommended approach: lead with risk mitigation, not growth.”
Nobody programmed that recommendation. No one wrote a rule that says “if procurement cycle is long AND culture is risk-averse AND CTO engagement is high, THEN suggest risk mitigation framing.” The system assembled it from memories, outcomes, and patterns accumulated over months of use.
The engine behind this runs 3 to 5 iterative search passes across all stored memories, outcome patterns, and observations. Each pass informs the next. The first pass might surface a pricing concern. The second pass, informed by that finding, might surface a competitor mention from six months ago. The third pass connects both to an industry trend. The result: a cross-cutting insight that no single data source reveals on its own.
This is the moment where a tool becomes a thinking partner. Not because it’s smarter than you. Because it has time you don’t. It connects what you said in January to what happened in March to what’s on your calendar tomorrow. And it does it at 2am on a Sunday while you’re asleep.

The Compound Effect
None of these systems is individually revolutionary. Agents that think in loops. Memory that decays and strengthens. Search that combines meaning with keywords. Feedback loops that connect one learning to another.
Each one is a solid engineering choice. But the compound effect is what happens when they work together over time. And this is where the story gets interesting.
Week 1. The system knows who you know. It has your contacts, your calendar, your email history. It’s aware of your world but has no opinions about it yet. It’s like a new colleague on their first day. Paying attention. Taking notes. Not yet ready to contribute.
Month 1. It knows your rhythms. Who you talk to often. Who you’ve been neglecting. How long your deals usually take at each stage. Where things tend to stall. It starts having opinions, and some of them are right. You catch yourself checking its morning briefing before you check your inbox.
Month 3. It knows what works for you specifically. Which approaches win which types of clients. Which signals predict that a deal is healthy or stalling. It starts surprising you. “You haven’t spoken to this contact in 45 days, they have an open deal, and the last two similar gaps in your data preceded lost deals.” You check. It’s right. That’s also when Relationship Decay becomes visible. Relationship Decay is the invisible erosion of connections that happens when no system is watching them, something we explored in Part 1 of this series. By month three, the system surfaces these patterns before you feel the consequences.
Month 6. It knows things about your business that you don’t. Not because it’s smarter. Because it never forgets a data point, never fails to connect two related observations, and never gets too busy to analyse what just happened.
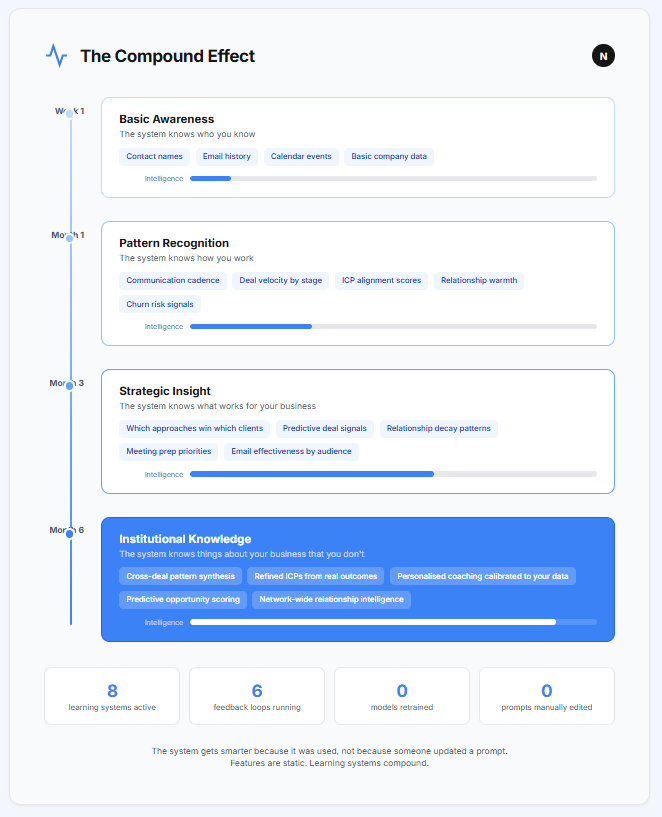
This is the difference between a feature and a learning system.
A feature is the same on day 1 and day 365. You get what you get. The interface might change when someone ships an update. But the underlying capability is static.
A learning system on day 365 is unrecognisable from day 1. And the person who built it couldn’t tell you exactly what it knows, because the knowledge was assembled from thousands of observations, feedback signals, and outcome patterns that no human catalogued. The system catalogued them itself.
That dashboard you saw at the top of the article?
Now you know what’s underneath.
Not a smarter model. Not a better prompt. Not a feature someone shipped last Tuesday. What’s underneath is a system that treated every interaction, every won deal, every thumbs down on a notification, every email that got a reply, as raw material. And it built something from that material that didn’t exist on day one.
Six months from now, the system running underneath that dashboard will be different from the one that exists today. Not because we updated it. Because people used it. Their deals, their patterns, their feedback, their relationships will have reshaped what the system knows, what it surfaces, and what it recommends.
Features are static. Learning systems compound.
The system gets smarter because it was used, not because someone updated a prompt.
If you want to see what six months of compounding looks like on real data, I’ll show you. Don’t put lipstick on a pig by wrapping AI onto a legacy CRM - take a look at a self learning growth system.
This is the AI architecture behind Nynch, the relationship-led growth platform. If you missed Part 1 on why your relationships decay invisibly without a system watching them, start here.